
分子構造と物性との定量的取扱いのススメ
Introduction to the Quantitative Handling of Molecular Structure and Properties
今田 知之
Tomoyuki Imada
合成や配合・分散などの開発実験における質量比・量論比・プロセス値と得られた物性データに関する解析では,物性データ(目的変数)に対する説明変数の情報量が少なく良好な予測モデルが構築できない事例が散見される。定量的構造物性相関(QSPR)は使用される化学物質の構造を数値化することで定量的に分子構造と物性の相関関係を探り,物性発現の因果関係や,最適構造を予測・導出しようとするものである。本報ではQSPRへの導入として,分子構造を数値化する基礎的な取扱いと社内適用例について述べる。
In the analysis of mass ratios, stoichiometry ratios, process values, and the obtained physical property data in development experiments such as synthesis, compounding, and dispersion, there are many cases where the amount of information on the explanatory variables for the physical property data (target var-iable) is too small to construct a good prediction model. Quantitative struc-ture-property relationship (QSPR) is a method to predict and derive the causal relationship between molecular structure and proper-ties by quantifying the structure of chemical substances used, and to predict the optimum structure. In this paper, as an introduction to QSPR, we describe the basic han-dling of quantifying molecular struc-tures and examples of in-house applications.
キーワード:定量的構造物性相関,QSPR,分子フィンガープリント,記述子,原子団寄与法
Key Words: Quantitative Structure Properties Rerationsip (QSPR), Molecular fingerprint, De-scriptor, Group contribution method
1 緒言
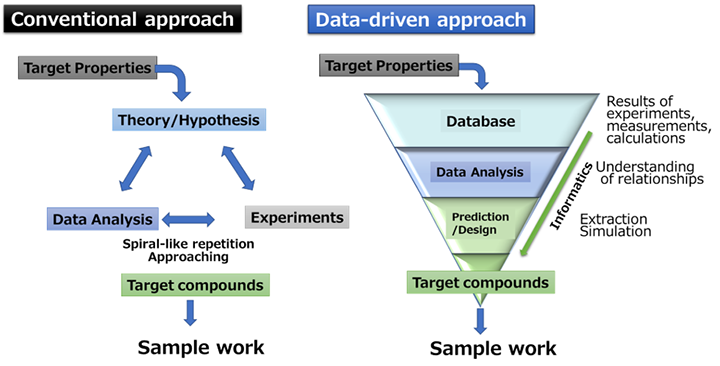
近年,科学分野における「第4のパラダイム」として,集約されたデータ(ビッグデータ)を起点に探究的アプローチをするデータ駆動型科学が注目されている1)。データ駆動型科学とは新たな機能を持った物質を専門的技術者が帰納的なPDCAサイクルで探索する従前の開発法に対して,データを起点にした情報科学(データサイエンス)的な統計・推論により演繹的に効率的且つ迅速探索を試みる開発アプローチである(Fig. 1)。DICに於いても,本年データサイエンスセンター(DSC)が創設され,データサイエンスを専門に取り扱う部署として技術の深耕と社内課題への展開を進めている。
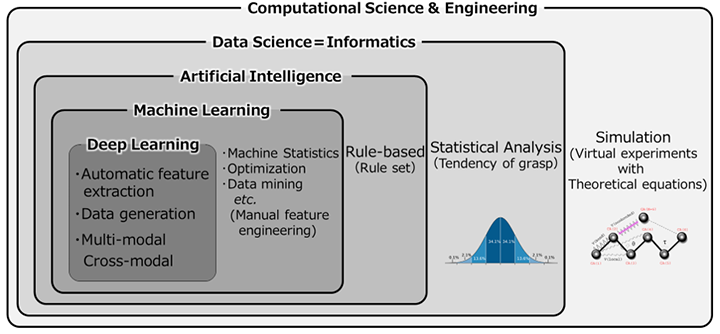
言語・画像処理や推論,課題解決,物質・システム設計などを人間に代わってコンピュータに行わせる技術を,一般的にAI(人工知能)やMI(マテリアルズインフォマティクス)と呼称し,それらは画像診断や無機化学の組成探索等に威力を発揮している2)。種々のご意見があることを承知ながら,混同されやすい技術分野の範囲をFig. 2に模式した。著者の理解ではデータサイエンスはデータ科学全般を表し,AIは個々で確立していない演算アルゴリズムを利用した技術全般を表現する。
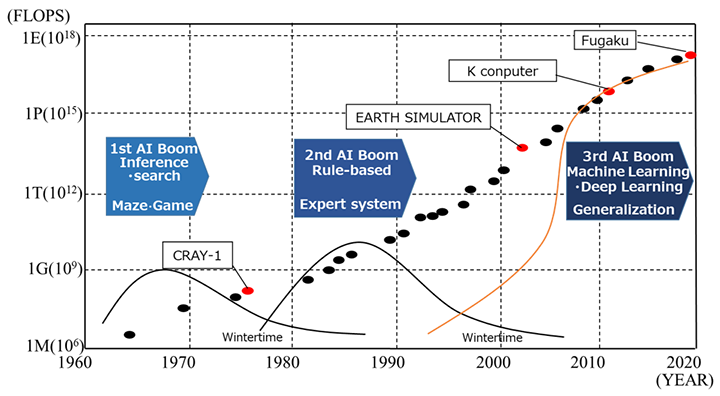
このAI/MIの発展はコンピューターの演算性能アップと無縁ではなく,データ演算による予測モデル構築に利用される識別や分類・回帰などの機械学習およびディープラーニングの発展はFig. 3に示すように演算速度と歩調を合わせるように栄枯盛衰を繰り返してきた。現在は第3次AIブームと呼ばれる波に乗っているかのように見受けられるが,ネットワーク化された高度情報化社会に引き波が訪れる様子は無く,今後もこの波は衰えることなく増幅すると予測される。
2 化学分野のインフォマティクス
インフォマティクスとは情報学,情報処理・システム,情報科学に関する技術分野を指すが,マテリアルズインフォマティクス(MI)などでのインフォマティクスという用語はデータ処理,情報・知識の統合,概念的・理論的な統合を意味して使用される。通常,各分野のベテラン技術者は,各々がその専門分野に対して独自理論(経験知)を構築し,日々の開発に従事しているものであるが,その経験知を正確に伝達・伝承することは困難であることが多い。技術者の数だけある膨大な経験知を集約・統合し,連綿と連なる製品開発の効率化に利用可能なデータ群として蓄積することが,今後の企業における製品開発の肝となる。
無機物質や素材の組成を直接的に探索するMIに対し,有機化合物に関するインフォマティクス技術はケムインフォマティクス(Cheminformatics)と独立して呼称される。その歴史は長く’60年代前半まで遡る3,4)。その歴史の長さに応じその原則的な取扱いは確立されていると言えるが,対象物質によりその取扱いを臨機応変に変える必要がある5-7)。
著者はDSCで分子構造と物性の相関を統計的に探る技術(定量的構造物性相関: Quantitative Struc-ture Properties Relationship)に関する開発を進めており,次節以降ではQSPRの概要について述べる。
3 QSPRの進め方
本節ではQSPRを実施するにあたっての分子構造をコンピュータ演算にかけるための前処理や数値化および,データ解析から分子構造の生成までの流れについて述べる。
緒言に述べた「ビッグデータ」の活用が世間では進んでいるが,残念ながら材料分野のデータはとても少ない「スモールデータ」であることが実情である。これまでの開発の主流が顧客ニーズの充足にフォーカスしたものであり,データとして連続性に欠けた飛び地的な数点ずつのデータが多く,解析のための集積を試みても100行に満たないものが多い。
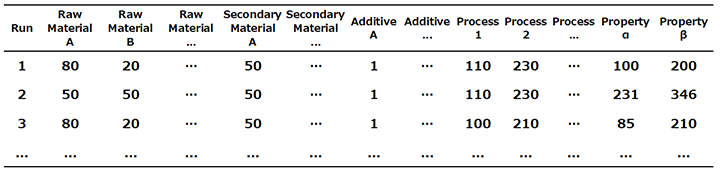
実際,著者らの手元に届く実験データはTable 1に示すような原料組成や配合組成と物性値が記された表が多く,そこに物性との相関性を検証するための分子構造情報等が記載されていることは稀である。まずは表記された数値の統計的な解析から着手するが,物性を説明するべき説明変数の表現力が不足する場面もあり,表現力を豊かにするために合成・分散・混錬・成形等のプロセスの情報の導入や,使用化合物の分子構造と物性の相関関係からの考察(QSPR)を検討する事例がほとんどを占める。
Table 1 Typical example of experimental data (a few dozen to a few hundred rows)
3.1 数値化の前処理
著者が化学分野の道を歩き始めた当時は合成に使用する原料の物性等を化学大辞典や化学便覧,Chemical Abstract等の書籍を紐解き手書きメモとして書き写していたが,現在はPubChem8),ChEMBLdb9)などオープンデータベースがネット上に存在し,以前より手軽に化学物質の構造式や性状値を入手可能となっている。
QSPRでは分子構造と物性の相関をコンピューター演算可能な形で取り扱う必要があり,手始めに化学物質の数値化を行う。得られた数値データと目標物性との統計解析,機械学習による物性予測モデル構築等を実施,最終的に目標物性到達の可能性検討や構造提案に至る。このとき数値化しやすい形式で分子構造を表現する必要があり,SMILES(Simplified Molecular Input Line Entry System)やMOL fileを利用する方法が代表的である。SMILESは1つの分子が1行の文字列として表現されるため,ファイルサイズを抑えられ,多くの分子を取り扱う場合に有効である。このSMILESの表記規則については英語版Wikipedia10)が参考になるが,ChemDraw11)などの構造式描画ソフトで構造式↔SMILESの相互変換が可能で規則を覚える必要は特にない。
3.2 物性計算値等による数値化(記述子)
現在,前述のChemDraw11)で約100種,オープンソースのRDKit12,13)で約200種,mordred14)で約1800種,商用ソフトのalvaDesc(旧DRAGON)15)で約5800種など驚くほど多様な記述子を得ることが可能である。しかし,これらの記述子は物理化学式や理論計算値として算出されたものであり重複や統計学的に等価な数値が多い。統計・機械学習における多重共線性やリークを排除するためには,使用する記述子-記述子間や記述子-物性データ間の相関関係を丁寧に洗い出し,物性との因果関係に迫る記述子の選択する必要があり取扱いに一定以上のスキルを要す。疑似相関を回避するためには化学とデータサイエンス双方の知識および経験が必要であり,選択眼の錬磨とノウハウの構築がQSPRの勘所で,DS,MIの専門家をDSCに集約する狙いはここにある。Table 2に代表的な記述子を次元別に例示した。
Table 2 Classification of descriptors by the dimensinality of their molecular representation5)

更に,それぞれの材料・技術分野に於いて慣用的に用いられる定量的パラメータも記述子として使用可能であり,社内独自の記述子を持つことが他社との差別化に非常に重要となることは自明である16)。最近では分子動力学計算(MD)や第一原理計算(DFT)などのシミュレーションで得られた計算値を記述子として利用したMIが盛んであり5,6),DSCでも鋭意取り組んでいる。
3.3 分子構造の数値化(フィンガープリント)
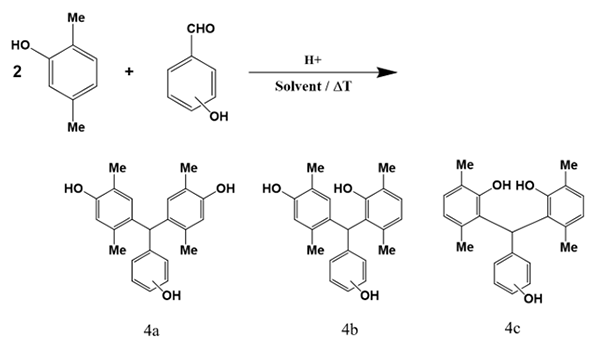
構造-物性との相関関係を見つめていく上での出発点が構造の決定である。分子構造を数値化するための手始めがChemDrawなどのツールを利用した構造式の描画になるが,この構造式の描画が最初の壁となる事例が多い。Fig. 4に2,5-ジメチルフェノールとヒドロキシベンズアルデヒドとを反応させたフェノール系3核体を例示する。
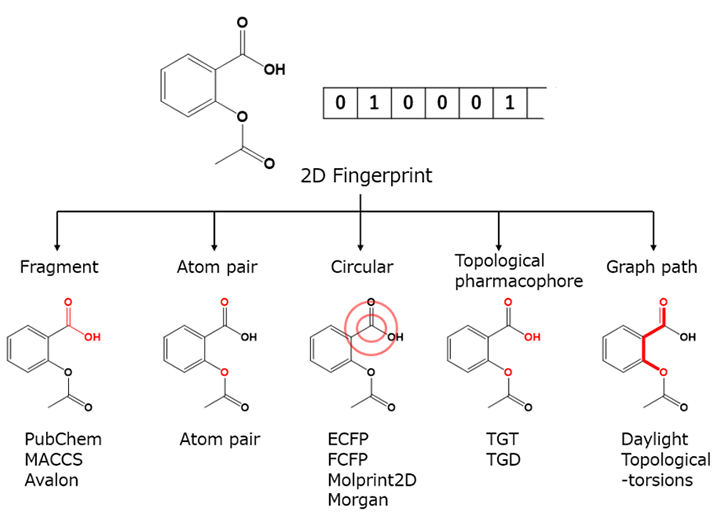
作成した構造式を前述のSMILESに変換し,フィンガープリント(分子指紋)と呼ばれるビットベクトル表現として構造の特徴を表すことが可能である。Fig. 5に代表的な2Dフィンガープリントを例示する。混合物,配合物などを表現する場合,ビットベクトルのモル比による幾何演算で表現可能であるため,構造的因子と物性の相関関係を探るうえで重要なテクニックだが,適切なビット表現を選択する必要があり,得られる情報の丁寧且つ繊細な取扱いが必須である。
例えば,Fig. 4の2,5-ジメチルフェノールにはOH基に対してo-,p-の2か所の反応部位が存在する。DICでは独自の配向制御と精製技術により4aの化合物を>99.7%の純度で得ることが可能であるため,使用する構造式を4aで表現している。通常の配向性から想定すると4b,4cの化合物も無視できない割合で存在するので,構造式の表現も全ての可能性を内包した表現にする必要がある。その場合混合物である4a,4b,4cを各々ビットベクトルに変換し,モル比に応じたベクトルの演算和として表現することが可能である。得られたベクトルは0/1表現ではなくなるが,構築する予測モデルに応じそのまま,あるいは閾値を設けた0/1表現に再変換して使用する。
3.4 オリゴマー/ポリマーの数値化
オリゴマー,ポリマーの分子構造はモノマーの結合部位を考慮すると多岐に渡るため,精密な分子構造の整理が複雑になる。一方,従来から原子団寄与法によりポリマー物性が推算できることがSP値,屈折率,Tg等で実証されている。そこで,QSPRにおいても,オリゴマー,ポリマーを部分構造(フラグメント)に分解し,各フラグメントカウント数を説明変数として物性間との解析を実施する原子団寄与法が熱力学的物性などの予測に広く利用されている17,18)。
原子団寄与法では対象のオリゴマー,ポリマーを部分構造(フラグメント)に分解し,各フラグメントカウント数を説明変数として物性間との相関関係の解析を実施する19-21)。フラグメントへの分解にはRECAP(Retrosynthetic Combinatorial Analysis Procedure)アルゴリズム等も利用可能であるが22),フラグメントが複雑化,肥大化する傾向があり,工業的に適用可能なフラグメントが生成されているかの吟味が必要である。また,使用する化学物質のTDSやSDSに記載のCAS No.や平均分子量,推奨配合比なども参考になるため,入手可能な資料をできうる限りの手段で集めておくことが肝要となる。
3.5 統計的解析と予測モデル構築
ビットベクトルや記述子で数値化された分子構造を物性データに対して解析を行うが,10変数程度であればExcelなどの表計算ソフトのツールを用いて多変量線形回帰やソルバーでの逆解析が可能である。先に述べた記述子やフィンガープリントの集合では説明変数が数100~数1000種に及ぶこともあるため,その取扱いにはscikit-learnなどのオープンソースの機械学習ライブラリや商用の機械学習プラットフォームを用いるのが通例である。機械学習を実施するにあたってはオープンソースのRやPythonを用いることが一般的であり,中でもPythonは入門~応用まで書籍や有志によるライブラリ開発が盛んで有用である。著者も前述のRDKitの利用や多量のデータの前処理,scikit-leanでの統計・機械学習処理,処理データのグラフ描画等にPythonを利用している。化学分野でPythonを利用するための入門書として有用な書籍を参考文献に挙げるが,まずは例に挙げられているスクリプトの写経をすることをお勧めする23,24)。
3.6 分子構造の生成
分子構造と物性との間に精度の高い予測モデルが得られると,そのモデルから有用な説明変数(部分構造(フラグメント),記述子)が特定できる。特定された有用な説明変数の各パラメータを最適化すれば所望の特性を有する分子構造も数学的に算出することが可能である。この自動化方法にBRICS(Breaking of Retrosynthetically Interesting Chemical Substructures)アルゴリズム25)や,船津らによるChemish26)などがある。さらに,算出された構造の合成難易度をスコア化するSAscore27),RAscore28)などのPythonライブラリを利用する方法などが挙げられる。これらは基本的に低分子薬物の合成に対して開発されたものであり,工業的なポリマー合成等には機能しない場合が多い。
4 低分子化合物への適用事例
4.1 構造の数値化
一般的に多価のフェノール系化合物は塩基性水溶液やメタノールなどのアルコール系溶剤,THFなどのエーテル系溶媒など,分子内に存在する水酸基と親和性の高い溶剤に良好な溶解性を有する。実際にはg/i線フォトレジストで使用されているm/p-クレゾールノボラックに塩基性水溶液難溶なものがあることは,当業者に周知の事実である。このように多価フェノール系化合物の検討では物性評価用サンプルの作成時に,固形サンプルの外観や分子構造のみで溶剤への可溶/難溶/不溶を見分けることが難しく,この段階での予測モデルを構築することは,効率的な物性評価とデータ蓄積を進めるために重要である。そこで,著者はフェノール系化合物の溶剤溶解性を分類予測するモデル構築を実施した。サンプル化合物の数値化はChemDrawとRDKitの記述子計算,およびRDKitで演算可能な数種のフィンガープリント化を実施した。種々の目標物性に対する,各種フィンガープリントで得られる回帰予測モデルの決定係数をTable 3に示す。
Table 3 Performance conparison of Moleculer Fingerprint
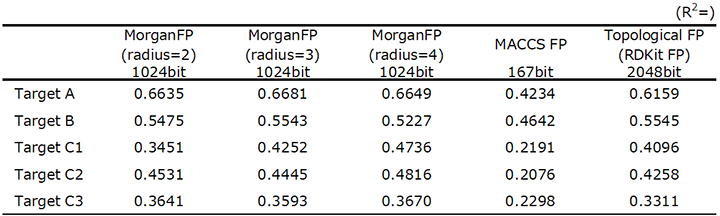
部分構造の数え上げであるMACCSフィンガープリントが全体的に低い決定係数となっているが,始点から始まる構造を表現するMorganフィンガープリントやTopologicalフィンガープリントは相対的に高い決定係数の予測モデルが得られる結果であった。このうち,Fig. 5に示すCircularフィンガープリントの一種であるMorganフィンガープリントで,同心円上4番目の原子まで演算を実施したビットベクトルの集合が,各目標物性にバランス良い反応を示したため,以降の検討にはこのビットベクトルの集合を使用した。
4.2 予測モデルの構築検討(分類)
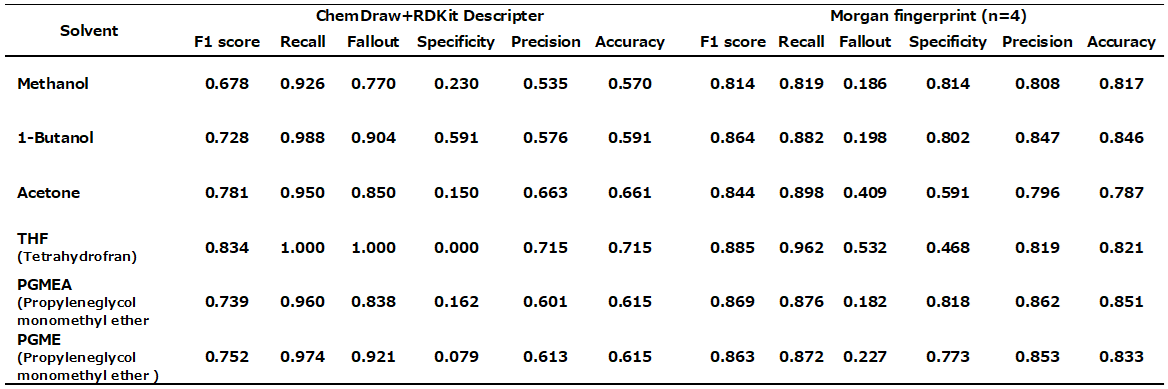
記述子およびフィンガープリントでフェノール化合物の代表的な各種溶剤への溶解性予測モデルを検討した結果をTable 4に示し,混同行列と各評価関数の算出式を下記する。

Table 4 Comparison of prediction model accuracy for various solvents
4.3 結果と考察
ChemDrawとRDKitから算出された約200の記述子から構築した予測モデルは,どの溶媒に於いても真陰性率(Specificity)が極端に低く,溶解する(陽性)と予測すれば7割程度は当たるという’予測モデル’とは言い難いものであった。
Fig. 6に記述子から構築した予測モデルのROC曲線と予測分布を示す。ROC(Receiver Operating Charac-teristic)曲線を簡単に説明すると,異常と正常を区別する閾値ごとに真陽性率(リコール)と偽陽性率(フォールアウト)を計算・プロットしたもので,閾値の変化に対する予測の切り分け具合を表す。
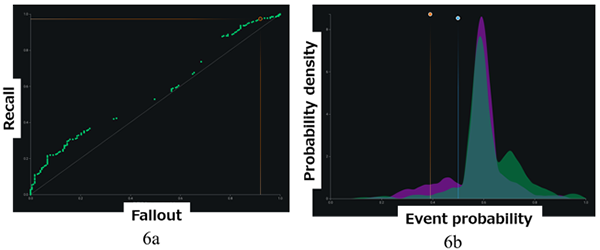
Fig. 6からほとんどの予測が重なっており分離不可能であることが見て取れる。この予測モデルでは水酸基数やlogP,pKa,沸点,van der Waals表面積など,フェノール系化合物の特徴を説明する典型的なパラメータが説明変数の重要度で上位に選出されるが,それらの数値でフェノール化合物を表現すると溶解する(陽性)/溶解しない(陰性)のどちらの化合物群もほぼ類似のものであることを意味する。このことから構造的な因子を含まない記述子群ではフェノール系化合物の溶解性を説明することは不可能であることが理解できる。
一方,Morganフィンガープリントから構築した予測モデルのROC曲線と予測分布をFig. 7に示す。構造的な特徴を表現できるフィンガープリントを使用することで溶解性の相違がはっきりと分離可能になり,精度の高い予測モデルが構築できた。
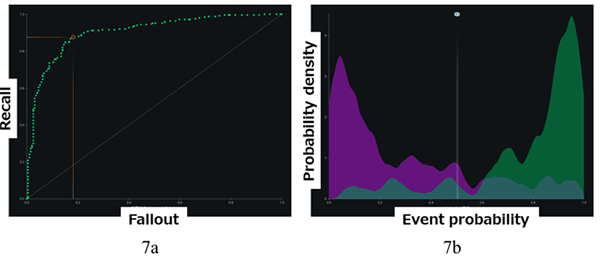
この予測モデルでは80,96,263,294,581,984など有効性の高いビット番号が選出される。ビットが1になったときに溶解性の識別に関係性が高いと選出されたビットの部分構造をFig. 8に例示する。
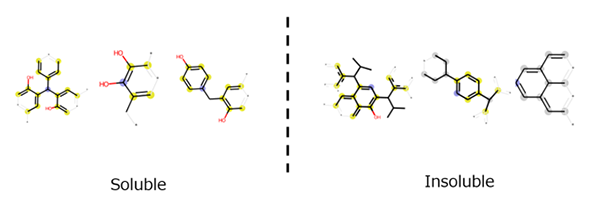
Fig. 8に示す部分構造から明らかであるが,PGMEA(プロピレングリコールモノメチルエーテルアセテート)のカルボニル基やエーテル基と親和性の高い水酸基を多く持つフェノール系化合物は溶媒和し易いが,その部分構造にスタッキング性の高い多環芳香族や内向性の水酸基を多く含むと溶媒和し難くなり溶解性が落ちることが示唆される。
以上の極端に相違する結果からフェノール系化合物の溶解性の差は単純な置換基の効果によるものではなく,その構造的な因子(分子内水素結合による水酸基の溶媒和阻害など)に大きく支配されていると考察できる。このことは前述のm/p-クレゾールノボラックの設計にも概念的には取り入れられており,蛸壺モデルなどとして模式化されている。
極端な例として,著者が学生時代の研究室で最初に合成した4-tert-ブチルカリックス[4]アレーン(Fig. 9)が挙げられる29)。この化合物は分子内に4つの水酸基を持つにも関わらず,それらが隣接しているために強い分子内水素結合を形成し,熱トルエンや熱キシレンなど可溶な溶剤が限定される。この性質を利用して再結晶などの精製が可能である30)。

5 ポリマーへの適用事例
5.1 構造の数値化
ポリマーはその部分構造を原子団として取り扱うことが有効な事例が多い。一例として著者が関わった特殊ノボラックの事例を示す。ターゲットは’高耐熱(高Tg:DSC Tg>150℃)’,’柔軟性(基板追従性:100μm塗膜にクラック無)’,’高アルカリ現像性(ADR:2.38%TMAHaq.現像で>2000Å/s)’とそれぞれ相反する物性を高度に兼備するノボラックの設計であり,常識的には非常に難易度が高いものであった。当初,構成するモノマー原料まで遡りフィンガープリント化などの手法をとり,プロセスの細かい変数化等を試みたが適切なモデル構築は難航した。
そこでモデルを単純化するために,ポリマーを原子団に分解するにとどめ 耐熱性と高アルカリ現像性を担保する主骨格A(Fig. 4aのノボラック),ポリマー主鎖に運動性の自由度をもたらす柔軟骨格B1,自由度を持つポリマー主鎖に柔軟性を付与する柔軟骨格B2の3ブロックに原子団化を行い,解析を進めることにした(Fig. 10)。ここで,柔軟骨格B1はポリマー主鎖に導入されるフェノール,クレゾール,キシレノール等からなるノボラック群,柔軟骨格B2は脂肪族鎖等の各種柔軟付与性が見込まれる置換基を表す31)。
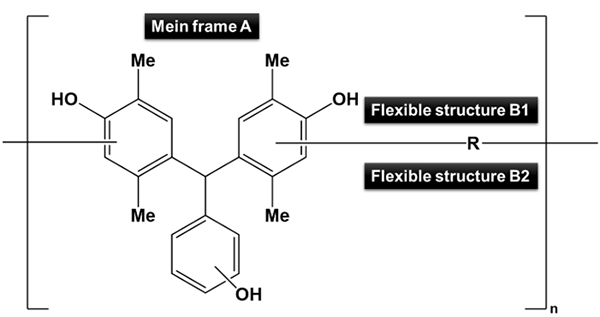
また,プロセス的な制約を設けずに設計を行うために,一般的なノボラックの合成法などの条件を排除して解析を行い,合成条件は得られた結果を具現化するプロセスを工夫することにした。
5.2 予測モデルの構築検討(回帰)
主骨格A,柔軟骨格B1,柔軟骨格B2-1,B2-2,B2-1+B2-2,分子量等を説明変数とし,目的変数にはDSCTg,ADR,耐クラック性を設定した。耐クラック性の評価は数値化を行うため,1,5,10,50μmで塗布,乾燥したSi基板上塗膜をレーザー顕微鏡観察,視野内を9分割したもののクラック数0~9を評価値とした。最終的な耐クラック性のモデルにおいては4種の評価値を4桁の数値にした後に対数変換した値(logNCP)を用いた。
5.3 結果と考察
DSCTg,ADR,耐クラック性(50μm)の予測モデルの予実プロットをFig. 11に示す。
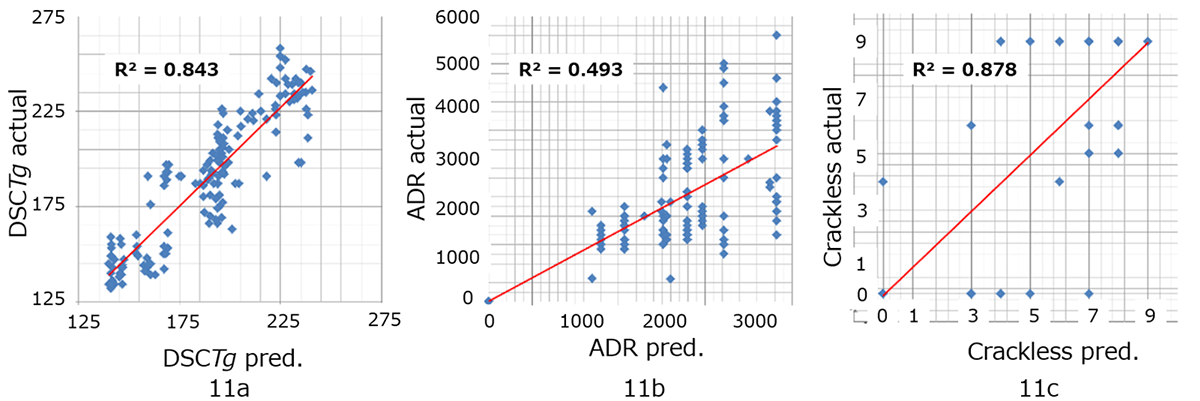
良好な決定係数を得られたDSCTgと耐クラック性の予測モデルに基づき,プロセスの工夫などで対応し得る500条件でグリッドサーチによる仮想実験を行った。その結果をFig. 12に示す。
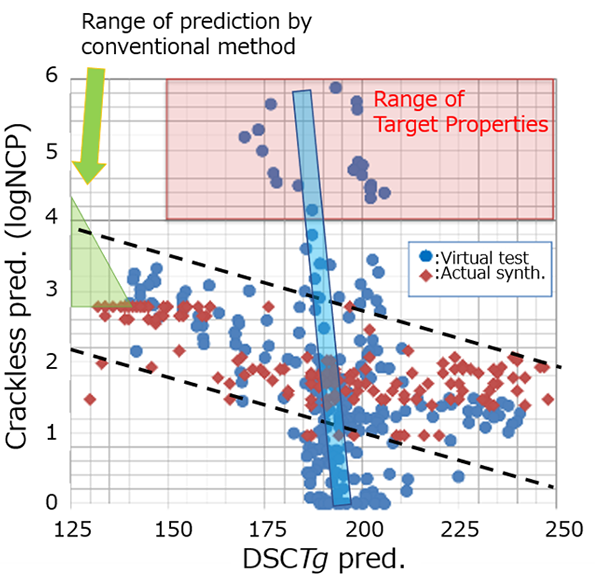
従来の合成プロセスに限定して予測される物性到達範囲はFig. 12の緑網掛範囲であり,実際の合成結果も黒破線で示される一定範囲を超えるものではなく,目標物性の範囲の達成には程遠いものであった。予測モデルにおいても同条件では同範囲に全て収まっており,予測モデルの妥当性が窺える。
一方,全く異なる新プロセスを含む形で想定した仮想実験結果は従来法とは異なる傾向(青網掛)を示す条件があり,34条件が目標物性に到達すると予測された。この結果を踏まえ,実証実験を行ったところDSC Tg(℃)>150, 100μm塗膜クラックなし,ADR(Å/s)>2000を全て兼備する16サンプルを得た。従来のノボラック樹脂との膜厚変化させたときの塗膜状態と樹脂性情(DSCTg,ADR)をTable 5に示す。
Table 5 Characterization of novel flexible and high heat-resistant Novolac resin

一般的な設計を施したノボラック樹脂は,Fig. 11からも明らかなとおり,積極的な分子内水素結合やπ-πスタッキング性を持つ多環芳香族,Fig. 4aなどの剛直な構造の導入,分子量の増大など分子運動を妨げることにより樹脂Tgを意図的に上げることができるが,堅脆くなり基板への追従性などが犠牲になる。Table 5 Ref 3はFig. 4aの構造を連結し剛直性を極めた結果,熱分解温度までDSC変曲点の無い樹脂となったが,良好な塗膜が得られないものであった。これに対し,新規開発のノボラック樹脂はDSC Tgが180℃と高温プロセスに十分な耐熱性を持ちながら100μm塗膜でもクラックを生じない。これは厚膜対応として流通している低分子量ノボラック(Table 5, Ref. 1)に対しても飛躍的なSi基板追従性を有する。
6 結言
本報では化学分野でデータサイエンスに興味を持たれる方むけに化学物質のデータとしての取扱いの概略を述べ,社内開発事例を挙げた。データサイエンスは大きなテーマから大上段に構えて開始するのでは無く,身近な実験サンプル作成を効率化などのExcel関数でも解析可能な小さなテーマから手を付けると親近感が湧き,モチベーションも保ちやすいと著者は感じている。
R&D的なテーマでは既存概念を破る物性を持つ化合物の開発を目指すことも多い。この場合,社内の既存プロセスを白紙に戻して,プロセスデータの無いデータセットから予測される結果を基に,合成プロセスから再構築するという,従来の開発法と視点を逆にしたデータドリブンなアプローチも必要になってくると考える。この観点からも前述の既存の常識を外れた物性を持つノボラック樹脂が,データドリブンな開発法で得られたことの意義は大きい。
著者は今後もデータサイエンスの観点からDICの新製品開発に関わっていく所存である。
謝辞
本報でのポリマー解析に多大なご助言をいただきました奈良先端科学技術大学院大学 金谷 重彦教授に感謝いたします。また,合成検討に協力いただきましたHou Shizheng氏,Sun Feng氏をはじめとしたQDIC第一研究室の皆様,物性測定に協力いただきました伊部 武史氏,長江 教夫氏をはじめとした機能材料技術2グループの皆様,およびレスポンシブルケア部化学物質情報管理グループ 椎根京子氏に感謝いたします。
参照文献
- T. Hey, S. Tansley, K. Tolle, Editors, “The FOURTH PARADIGM Data-Intensive Sci-entific Discovery”, Microsoft Research (2009)
- 技術情報協会編, “マテリアルズ・インフォマティクスによる材料開発と活用集”,技術情報協会 (2019)
- T. Fujita, J. Iwasa, C. Hansch, J. Am. Chem. Soc., 86, 5175 (1964)
- R. Todeschini, V. Consonni, “Molecular Descriptors for Chemoinformatics”, Wiley-VCH, Weinheim (2009)
- T. Engel, J. Gasteiger, “Cheminformatics - Basic Concepts and Methods”, Willy-VCH, Weinheim (2018)
- T. Engel, J. Gasteiger, “Applied Cheminformatics – Achievements and Future Opportunities”, Willy-VCH, Weinheim (2018)
- J. Gasteiger, T. Engel, 船津公人監訳, “ケモインフォマティックス”, 丸善,東京 (2005)
- PubChem: https://pubchem.ncbi.nlm.nih.gov
- ChEMBLdb: https://www.ebi.ac.uk/chembl
- Simplified molecular-input line-entry system: https://en.wikipedia.org/wiki/Simplified_molecular-input_line-entry_system
- ChemDraw,PerkinElmer: https://perkinelmerinformatics.com/products/research/chemdraw/
- RDKit: https://www.rdkit.org/
- https://www.rdkit.org/docs/GetingStartedInPython.html#list-of-available-descriptors
- H. Moriwaki, Y-S. Tian, N. Kawashita, T. Takagi, Journal of Chemoinformatics, 10, 4 (2018): https://github.com/mordred-descriptor/mordred
- alvaDesc, Alvascience Srl.: https://www.alvascience.com/alvadesc/
- 石森元和, DIC Technical Review 1999, 5, 1 , (1999)
- D. W. Van Krevelen, Properties of Poly-mers. Their Estimation and Correlation with Chemical Structure, 2nd Ed., Elsevier (1976)
- S. Goto, M. Arakawa, K. Funatsu, J. Com-put. Aided Chem, 10, 30 (2009)
- Fredenslund, R. L. Jones, J. M. Prausnitz, AIChE J., 21, 1086 (1975)
- K. M. Klincewicz, R. C. Reid, AIChE J., 30, 137 (1984)
- L. Constantinou, R. Gani, AIChE J., 40, 1697 (1994)
- X. Q. Lewell, D. B. Judd, S. P. Watson, M. M. Hann, J. Chem. Inf. Comput. Sci., 38, 511 (1998)
- 船津公人, 柴山翔二郎, “実践マテリアルズインフォマティクス-Pythonによる材料設計のための機械学習-”, 近代科学社, 東京 (2020)
- 金子弘昌, “化学のためのPythonによるデータ解析・機械学習入門”, オーム社, 東京 (2019)
- J. Degen. C. W. Gerlach, A. Zaliani, M. Rarey, ChemMedChem, 3, 1503 (2008)
- M. Arakawa, Y. Yamada, K. Funatsu, J. Comput. Aided Chem, 6, 90 (2005),: Chemish: http://www.cheminfonavi.co.jp/chemish/
- P. Ertl, A. Schuffenhauer, J. Cheminformatics, 1, 1:8 (2009)
- A. Thakkar, V. Chadimova, E. J. Bjerrum, O. Engkvist, J. -L. Reymond, Chem. Sci.,12,2229 (2021)
- C. D. Gustche, B. Dhawan, K. H. Ho, R. Muthnkrishonon, J. Am, Chem. Soc., 103, 378 (1981)
- C. D. Gustche,Acc. Chem. Res., 16, 16 (1983)
- DIC株式会社, 特許第6341348号
著者紹介(執筆時)

今田知之
DIC株式会社
技術統括本部
データサイエンスセンター
サイエンティスト
