
Deep Learningモデルの設計指針
Design Guidelines for Appropriate Deep Learning Models
石井 融
Toru Ishii
Deep Learningは,訓練データから特徴量を自動抽出できる唯一の機械学習手法である。この効果は絶大であり,予測精度の観点でDeep Learningは他手法を圧倒する。しかしながら,Deep Learningは訓練データに適した予測モデル設計に技術者が試行錯誤しなければならず,実践難度の観点ではモデル設計を要しない他手法に劣る。多くの技術者が適切なDeep Learningモデルを設計して優れた予測精度を享受できるように,本稿では Deep Learningモデルの設計指針を提供する。
Deep learning has capability to automatically extract informative features from training data, which any other machine learning methods do not have. This unique capability makes deep learning overwhelm other methods in terms of prediction accuracy. From a practical perspective, however, deep learning is less tractable than the others because it requires burdensome manual design of pre-diction model while the others dose not. In this article, design guidelines for appropriate deep learn-ing models are provided for the purpose of introduction to the deep learning world. The author hopes that this article helps readers become skilled model designers and enjoy deep learning’s ex-cellent prediction accuracy.
キーワード:Deep Learning,FFNN,RNN,CNN,機械学習
Key Words: Deep Learning, FFNN, RNN, CNN, Machine Learning
1 緒言
Deep Learningとは「Deep Neural Networkを用いた機械学習の一手法」である。おそらく,多くの読者は冒頭からの不慣れな専門用語に戸惑っていることであろう。そのような専門外の技術者のために,本節ではまず「機械学習」と「Deep Neural Network」の両専門用語について概説し,他の機械学習手法には無いDeep Learningのメリット・デメリットについて述べる。それらの基礎知識を踏まえ,本稿が提供する「Deep Learningモデルの設計指針」の意義を本節末に整理する。本稿理解に必要な要点のみを数式ではなく定性的な言葉で表現したので,多少の不明点があっても読み進めていただきたい。Deep Learningが他の機械学習手法と一線を画すブレイクスルーであることを感じ取れるはずである。
Deep Learningの技術的詳細を習得したい読者は,参考文献1-4)にあたられたい。Deep Learning技術発展のターニングポイントとなった著名なDeep Learningモデルについても知見が深まるだろう。Deep Learningを実践したい読者は,Tensorflow5),Keras6),Pytorch7)などのオープンソースライブラリの活用を推奨する。これらのライブラリはユーザフレンドリなAPIを提供しており,わずか数十行のコードでDeep Learningモデルを構築・訓練できるだろう。
1.1 機械学習とは
機械学習と聞くと非常に難解で高尚な技術に感じるかもしれないが,その要点は案外容易に理解できる。機械学習の中で最も一般的な「教師あり学習」に着目すると,入力・モデル・出力・目標の4要素と,訓練・予測の2ステップを理解すればよい(Fig. 1)。それらの要点は以下の通りである。
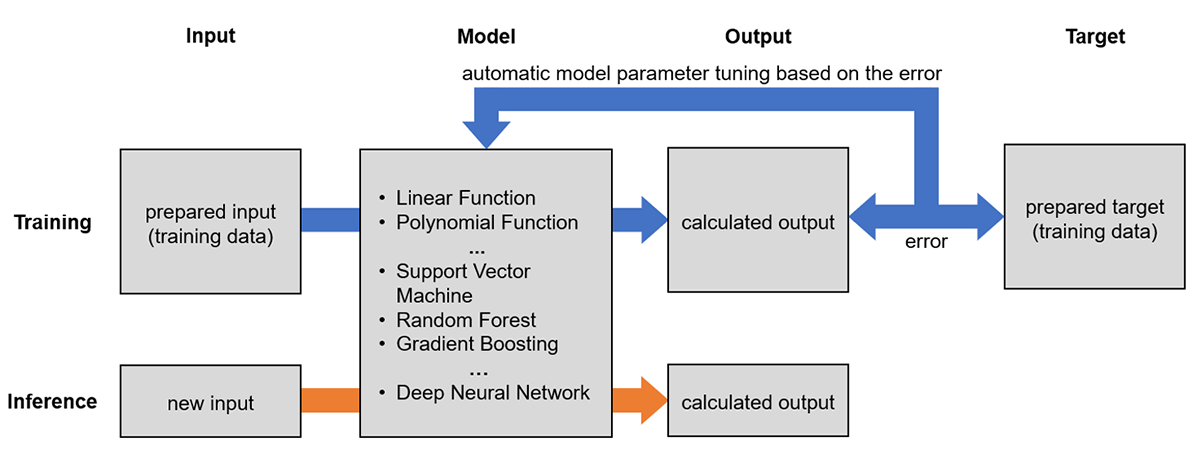
- 数値表現された入力を,数式表現されたモデルに代入して,算出された結果が出力,出力して欲しい値が目標である。
- モデルにはパラメータがあり,同じ入力を代入しても,パラメータによって出力が変動する。
- 予め準備した入力・目標のセット(訓練データ)において,入力をモデルに代入して算出した出力≒目標となるようパラメータを自動調整するステップが訓練である。
- 新規の入力を,訓練後のモデルに代入して,対応する出力を算出するステップが予測である。
そして,実は多くの技術者が既に機械学習を実践している。例えば,実験条件と物性の実測データから回帰直線を引き,新規の実験条件における物性を予測する何の変哲もない作業は,機械学習そのものである。前述の要点に当てはめれば,以下の通り表現できる。
- 実験条件の数値(入力)を,一次関数(モデル)に代入して,算出された結果が出力,出力して欲しい値が物性(目標)である。
- 一次関数には傾き・切片(パラメータ)があり,同じ入力を代入しても,傾き・切片によって出力が変動する。
- 実測した実験条件・物性のセット(訓練データ)において,実験条件を一次関数に代入して算出した出力≒物性となるよう傾き・切片を自動調整するステップが訓練である。
- 新規の実験条件を,訓練後の一次関数に代入して,対応する出力を算出するステップが予測である。
機械学習を経験したことのある読者は,機械学習としてSupport Vector Machine8)やGradient Boosting9)などの個別手法を連想したかもしれないが,これらはモデルを一次関数から複雑な数式に替えたに過ぎない。即ち,入力と目標の関係が複雑な場合でも,出力≒目標を目指してパラメータを自動調整できるよう工夫された複雑な数式である。複雑な数式を理解せずともパラメータは自動調整されるので,DataRobot10)などの機械学習ツールを使えば誰でも簡単に個別手法を実践できる。
機械学習を実践する上で注意すべき点は,個別手法の数式は複雑であっても「固定」されている点である。一次関数の傾き・切片を変えるだけでは直線が曲線にならないように,いくら複雑な数式でもパラメータを変えるだけで表現できる曲線のバリエーションには限界がある。従って,入力と目標の関係が極めて複雑な場合は,いくらパラメータを自動調整しても出力≒目標を達成できない。換言すれば,目標との関係ができるだけ単純な入力を準備することが機械学習実践のコツであり,その準備を特徴量エンジニアリングと呼ぶ。例えば,前述の実験条件と物性の例において実験条件が温度プロファイルの場合,温度プロファイル自体を入力とはせずに,昇温速度やホールド時間など物性に「影響していそうな特徴量」を技術者が推考して準備する。対象データのドメイン知識を踏まえた特徴量推考を試行錯誤すれば,出力≒目標を達成できる可能性が高まる。ただし,技術者が想定外の特徴量や入手不可能な特徴量が存在すると,絶対に出力≒目標を達成できないことに注意されたい11)。
1.2 Deep Neural Networkとは
Neural Networkとは,線形演算やRectified Linear Unit(ReLU)関数などの比較的単純な非線形演算を多数組合せたモデルである。機能性に応じて単一または複数の演算をまとめた「レイヤ」と呼ばれる基本単位があり(Table 1),多数のレイヤを「深く」積み重ねたモデルがDeep Neural Networkである。レイヤの積み重ね方は自由であり,自身の機械学習タスクに応じて設計が可能である。この設計自由度こそが,数式が固定されている他の機械学習手法には無いDeep Neural Networkならではの特色である。
Table 1 Commonly used layers in deep learning models

古典的なNeural Networkでは,「Neural」という名の通り「生物神経系」の動作を模倣したレイヤ12-14)が提案されていた。その発展形であるDeep Neural Networkでは,もはや神経系の模倣という概念に捉われることなく,予測精度向上に有効な多種多様なレイヤが提案されている。Deep Neural Network,即ち,Deep Learningの習得では,「Neural」という言葉に惑わされないよう注意されたい。
Deep Neural Networkにおけるパラメータの自動調整には,誤差逆伝播法が用いられる15)。この手法の解説は本稿目的から逸れるため割愛するが,ランダム初期値のパラメータに対して自動調整を繰り返し,徐々に収束させることは記憶に留められたい。
1.3 Deep Learningのメリット・デメリット
本節冒頭で述べた通り,Deep LearningとはDeep Neural Networkをモデルに用いた機械学習である。即ち,自由にレイヤを積み重ねたモデルを用いた機械学習である。それでは,モデルの設計自由度はDeep Learningにどのようなメリットとデメリットをもたらすのだろうか。
非常に喜ばしいメリットは,入力と目標の関係が極めて複雑な場合でも特徴量エンジニアリングを行わずに訓練できることである。これは,単にレイヤを膨大に積み重ねて極めて複雑な数式をモデルに用いるという意味ではない。目標に強く影響する「有意な特徴量」を入力から「自動抽出」できるレイヤが提案されており,この特徴抽出レイヤを積み重ねることにより,出力≒目標を達成するのである。前述の温度プロファイルと物性の例で言えば,温度プロファイル自体を入力として訓練すると,特徴抽出レイヤでは有意な特徴量を抽出するようにパラメータが自動調整され,後続レイヤでは有意な特徴量から算出した出力≒目標となるようにパラメータが自動調整される。特徴抽出レイヤは技術者が想定外の特徴量も自動抽出できることに注意されたい。この特徴量の自動抽出は効果絶大であり, Deep Learningが誕生した画像認識競技会ILSVRC 201216,17)では,他の機械学習手法に圧倒的大差をつけて優勝した。
一方,設計自由度がもたらすデメリットは二点ある。一点目は,モデル設計に熟練を要することである。モデルを設計するためには,①Table 1に示す各レイヤの機能と内部演算,②著名なDeep Learningモデルの設計思想,の理解が必須となる。①を理解すれば既存モデルを自由自在に改良できる中級者,②まで理解すればゼロからモデルを自由自在に設計できる上級者とイメージすればよい。デメリットの二点目は,大量の訓練データを要することである。特徴抽出レイヤは強力である反面,訓練データ内で目標と線形・非線形に偶然相関した誤特徴量も抽出してしまう。誤特徴量の抽出が起こると,訓練データでは過度に出力≒目標を達成する一方,偶然相関した情報を含まない新規の入力では出力≠目標となり,予測モデルとして全く役に立たなくなる。このようにモデルが訓練データに過度に適合した状態を過学習と呼ぶ。過学習を回避する最も効果的な方法は,大量の訓練データを準備して目標と偶然相関する情報を抑制することである。
1.4 目的
本稿では,デメリットの一点目を解消する一助として「Deep Learningモデルの設計指針」を提供する。次節以降,数値テーブル・時系列データ・画像データの順に使用する各レイヤの機能と内部演算を概説し,それらの積み重ね方の基本指針について述べる。Deep Learning の未経験者にはモデル設計の雰囲気体験に,初学者にはモデル設計の糸口に,中級者にはモデル設計の備忘録になれば幸甚である。
2 数値テーブルを扱うモデルの設計
数値テーブルは,行方向にサンプル,列方向に入力と目標を並べた最も一般的なデータ表現である。例えば,行方向にサンプル,列方向に配合組成比と物性を並べた組成物データをイメージすればよい。そして,機械学習タスクとしては,配合組成比から物性を予測するモデルの構築をイメージすればよい。
数値テーブルにおいて入力に対するモデル出力≒目標を達成するためには,各入力単独の特徴量だけでなく,入力間の相互作用に関連する特徴量も抽出しなければならない。Deep Learningモデルでは,加重平均演算と単純な非線形演算の繰返し(Fig. 2)により,そのような特徴抽出を実現する。一般に,加重平均を行うレイヤをFull Connectionレイヤ,単純な非線形演算を行うレイヤをActivationレイヤ,モデル全体をFFNN(Feed Forward Neural Network)と呼ぶ。本節では,両レイヤの概略とFFNN設計の基本指針について述べる。
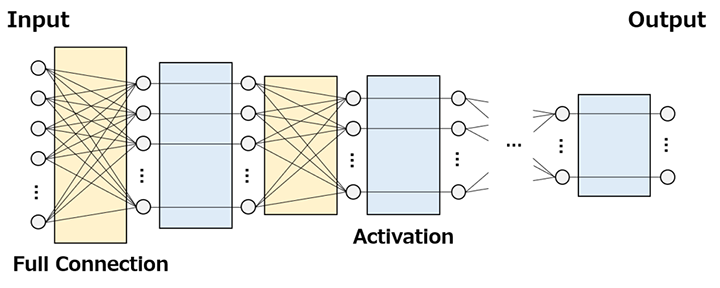
2.1 Full Connectionレイヤ
相互作用に関連する特徴量を表現する最も単純な方法が加重平均である。即ち,相互作用の強さを加重平均の重みパラメータとして表現し,訓練する。1つの重みパラメータが非0,残りの全重みパラメータが0に自動調整されれば,入力単独の特徴量も抽出できることに注意されたい。Full Con-nectionレイヤは重みパラメータの「セット」の数を設定することができ,セット数に応じた複数の特徴量を抽出することができる。
興味深いことに,Deep Learningモデルはレイヤを積み重ねるほど複雑な特徴量を抽出できるようになる。Full Connectionレイヤを積み重ねた場合,入力に近いレイヤでは単純な相互作用に関連する特徴量,入力から遠いレイヤでは複雑な相互作用に関連する特徴量が抽出される。
2.2 Activationレイヤ
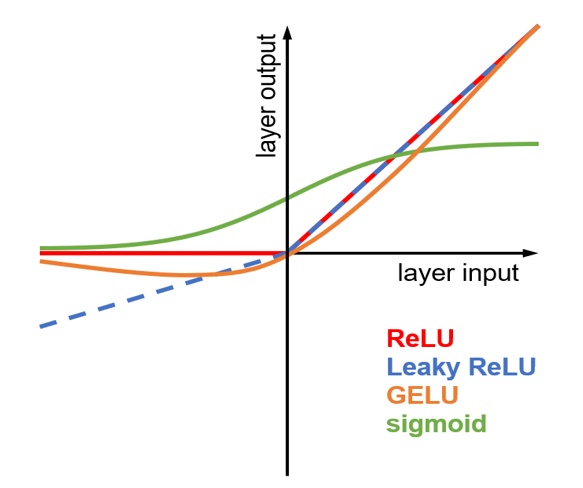
Full Connectionレイヤは加重平均演算であるため,どんなに積み重ねても入力と出力は線形関係の域を出ない。入力と目標が非線形関係であっても出力≒目標を達成できるように,出力に非線形性を与えることがActivationレイヤの機能である。古典的なNeural Networkでは生物神経系の非線形動作を模したSigmoid関数がActivationレイヤの主流であったが,現在のDeep Leaningでは神経系の模倣に捉われることなくReLU,Leaky ReLU,GELUなどのReLU系関数(Fig. 3)が主流となっている。Activationレイヤの非線形演算には訓練対象のパラメータが無いことに注意されたい。
2.3 FFNNの設計
FFNNの設計では,Full ConnectionレイヤとActivationレイヤを交互に複数回積み重ね,徐々に複雑かつ非線形の強い相互作用特徴量を抽出することが一般的である。ただし,最後のActivationレイヤはReLU系関数ではなく,機械学習タスクに応じて回帰問題は無し,二値分類問題はSigmoid関数,多値分類問題はSoftmax関数を使用する。Sigmoid関数は0~1の値を出力し,どちらか一方の分類クラスに属する確率として扱うことができる。Softmax関数は0~1の値を分類クラスと同数出力し,各分類クラスに属する確率として扱うことができる。
積み重ねるレイヤの総数や各Full Connectionレイヤが抽出する特徴量の数は訓練データ次第であり,様々な条件で訓練して最適な条件を見極める必要がある。
3 時系列データを扱うモデルの設計
時系列データは,行方向にサンプル,列方向に順序立てられた一揃いの入力と目標を並べたデータ表現である。例えば,行方向にサンプル,列方向に温度プロファイルと終点物性を並べた工程データをイメージすればよい。そして,機械学習タスクとしては,温度プロファイルから終点物性を予測するモデルの構築をイメージすればよい。
時系列データを扱うDeep Learningモデルでは,一揃いの入力をモデルへ一括入力するのではなく,順序立てに従ってモデルへ逐次入力する(Fig. 4)。逐次入力の回数は系列長に応じて自動的に制御されるため,系列長の違うデータを同じモデルで扱うことができる。
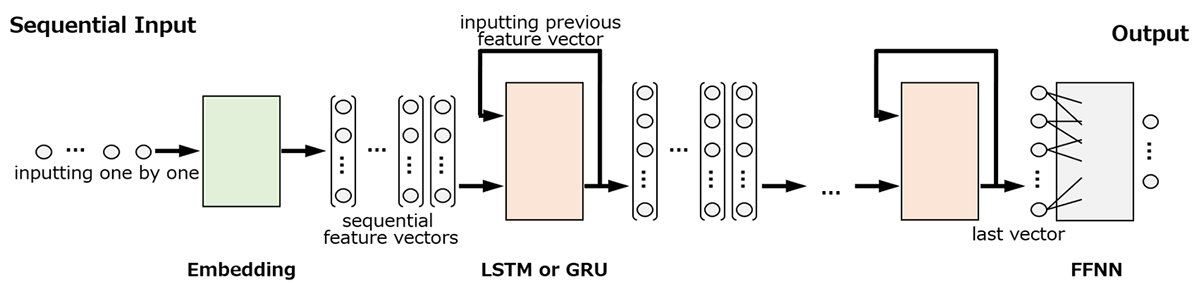
一揃いの入力に対するモデル出力≒目標を達成するためには,過去の逐次入力から抽出した特徴量を加味しつつ,現在の逐次入力から現在の特徴量を抽出しなければならない。Deep Learningモデルでは,前時刻にレイヤが抽出した特徴量を現時刻に当該レイヤへ入力するループ構造により,そのような特徴抽出を実現する。ループ構造を有する代表的なレイヤがLong Short-Term Memory(LSTM)レイヤ18)およびGated Recurrent Unit(GRU)レイヤ19)であり,それらを含むモデル全体をRNN(Recurrent Neural Network)と呼ぶ。本節では,両レイヤの概略とRNN設計の基本指針について述べる。
ところで,SMILES表記20)した化学構造などの文字列は,文字種と数値インデックスを対応付ければ時系列データと見なせる(Fig. 5)。ただし,文字種を区別する符号に過ぎない数値インデックスは大小関係に意味が無く,モデルに直接入力すべきではない。このような場合,数値インデックスを有意な特徴量へ変換するEmbeddingレイヤを使用する。本節ではEmbeddingレイヤも概説する。
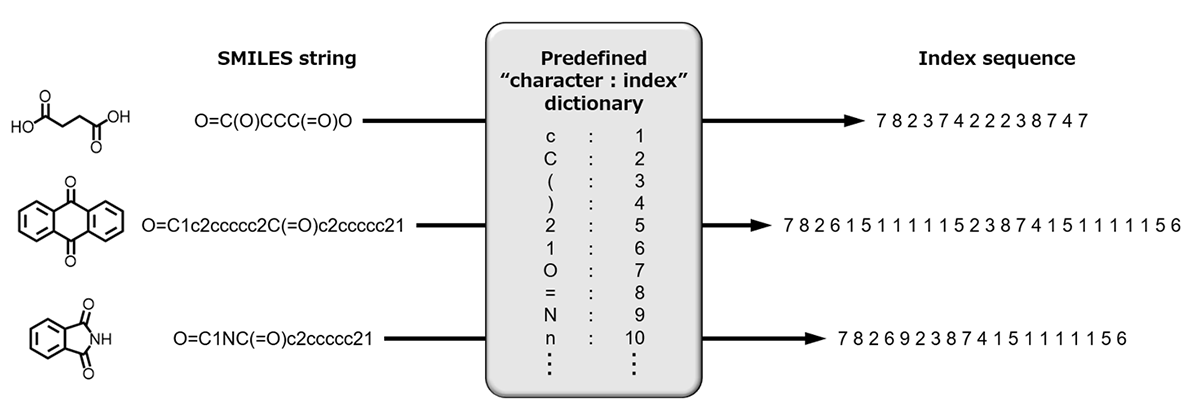
なお,本稿では時系列データを扱う最新ブロック(レイヤの集合体)であるAttention機構21-23)については概説しない。Attention機構は予測性能および訓練時間の観点でLSTMレイヤおよびGRUレイヤを圧倒するが,動作原理の理解にはDeep Learningの実践経験が必要である。本稿を参考にDeep Learningを実践した後にチャレンジすることを推奨する。
3.1 LSTMレイヤ
ループ構造を用いて前時刻にレイヤが抽出した特徴量を現時刻に当該レイヤへ入力すると,現時刻では前時刻の特徴量を参照することができ,前時刻の特徴量を「記憶」したことと同義となる。そして,前時刻の特徴量と現在の逐次入力から現在の特徴量を抽出して記憶する工程は「記憶の更新」と見なせる。LSTMレイヤの記憶更新演算は忘却すべき情報と追記すべき情報を自動制御する機構を備えており,LSTMレイヤを訓練すると有意な特徴量へ記憶更新されるよう自動制御機構のパラメータが自動調整される。LSTMレイヤは抽出する特徴量の数を設定することができ,設定した特徴量数が記憶の大きさとなる。
LSTMレイヤの出力は,各時刻に抽出した特徴量のシーケンスと,最終時刻に抽出した特徴量のどちらにも設定できる。特徴量シーケンスを出力するよう設定すれば次レイヤにもLSTMを積み重ねることができ,入力した時系列データに潜在する複雑な特徴量も抽出できるようになる。
また,LSTMレイヤの出力は,順序立て通りに逐次入力した場合の特徴量だけでなく,順序立て通りおよび逆順に逐次入力した2パターンの特徴量を統合するようにも設定できる。後者の設定をBidirectionalと呼び,2パターンの特徴量の統合は加算,積算または結合が一般的である。訓練データの系列長が非常に長いため,初期の逐次入力から抽出した特徴量が記憶更新過程でかき消されてしまう場合は,Bidirectionalの設定を使用すればよい。
3.2 GRUレイヤ
LSTMレイヤが備える記憶更新の自動制御機構を簡略化したものがGRUレイヤである。計算資源が乏しい場合や訓練時間を短縮したい場合は,LSTMレイヤの替わりにGRUレイヤを使用すればよい。
3.3 Embeddingレイヤ
Embeddingレイヤの機能は,数値インデックスを有意な特徴量へ変換することである。Embeddingレイヤの変換演算は数値インデックスを索引,パラメータを内容とした「辞書」を備えており,入力された数値インデックスに対応するパラメータを出力する。Embeddingレイヤを訓練するとパラメータ自体が有意な特徴量となるよう自動調整される。
3.4 RNNの設計
RNNの設計では,入力する時系列データが文字列の場合はEmbeddingレイヤを最初に使用し,文字列でない場合はEmbeddingレイヤを使用しない。その後にLSTMレイヤまたはGRUレイヤを複数回積み重ね,最後にFFNNを積み重ねることが一般的である。LSTMレイヤまたはGRUレイヤの積み重ねでは,最終レイヤ以外は特徴量シーケンスを出力するよう設定することに注意されたい。一方,最終レイヤは最終時刻に抽出した特徴量を出力するよう設定し,FFNNへの入力とする。
積み重ねるLSTMレイヤまたはGRUレイヤの総数や各レイヤが抽出する特徴量の数は訓練データ次第であり,様々な条件で訓練して最適な条件を見極める必要がある。
4 画像を扱うモデルの設計
画像データは,Red・Green・Blue各色の明るさ平面分布を「グリッド状に分割」した三次元グリッド状のデータ表現である(Fig. 6)。入力に対する目標は別途数値テーブルとしてデータ表現する場合が多い。例えば,放熱複合材料の電子顕微鏡画像群と熱伝導率の数値テーブルをイメージすればよい。そして,機械学習タスクとしては,電子顕微鏡画像から熱伝導率を予測するモデルの構築をイメージすればよい。

画像データにおいて入力に対するモデル出力≒目標を達成するためには,目標に影響する因子が画像中の何処にあっても同等の特徴量として抽出しなければならない。Deep Learningモデルでは,画像中の位置を変えながら同一の局所的な特徴抽出・特徴圧縮を繰り返すことにより,そのような特徴抽出を実現する(Fig. 7)。一般に,局所的な特徴抽出を行うレイヤをConvolutionレイヤ24),局所的な特徴圧縮を行うレイヤをPoolingレイヤ24),それらを含むモデル全体をCNN(Convolutional Neural Network)と呼ぶ。本節では,両レイヤの概略とCNN設計の基本指針について述べる。
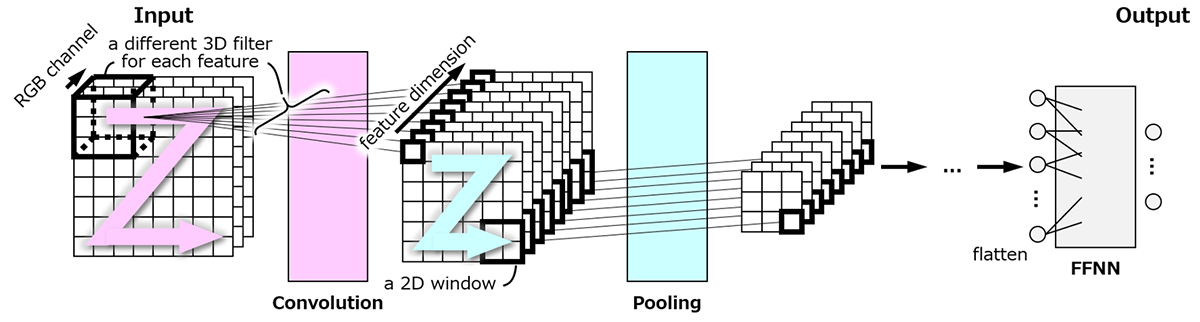
ところで,X線CTなどの3D画像や製造ラインモニタリングなどの動画像は,空間軸または時間軸が追加された高次元の画像データである。また,各種化学分析結果のスペクトルは,信号強度を一次元グリッドに分割した低次元の画像データと見なせる。ConvolutionレイヤおよびPoolingレイヤは,内部演算の次元を容易に変更することができ,これらの高・低次元画像も扱うことができる。「画像」という言葉に捉われず,CNNはグリッド状のデータを扱うDeep Learningモデルと理解すればよい。
4.1 Convolutionレイヤ
目標に影響する因子が画像中の何処にあっても同等の特徴量として抽出できるように,画像中の位置を変えながら,フィルタと局所画像との積和演算を繰り返す。即ち,フィルタ各要素を重みパラメータとした局所画像の加重平均(積和演算)により局所的特徴量を抽出するが,画像中の何処でも共通の重みパラメータを使用ことになる。Convolutionレイヤはフィルタの数を設定することができ,フィルタ数に応じた複数の特徴量を抽出することができる。
フィルタとの積和演算は加重平均であるため,どんなにConvolutionレイヤを積み重ねても入力と出力は線形関係の域を出ない。入力と目標が非線形関係であっても出力≒目標となるよう,Convolutionレイヤの後にActivationレイヤを積み重ねることが一般的である。ConvolutionレイヤおよびActivationレイヤを積み重ねることにより,入力した画像データに潜在する複雑な特徴量も抽出できるようになる。
4.2 Poolingレイヤ
Convolutionレイヤは局所的な特徴抽出であるため,どんなに積み重ねても画像全体の特徴量を抽出できない。隣接した複数の局所的特徴量を1つの中域特徴量に圧縮することがPoolingレイヤの機能である。代表的な特徴圧縮演算は,複数の局所的特徴量の最大値を中域特徴量に採用するMax Poolingや,平均値を採用するAverage Poolingである。Poolingレイヤの特徴圧縮には訓練対象のパラメータが無いこと,圧縮後の中域的特徴量は画像サイズが減少することに注意されたい。
4.3 CNNの設計
CNNの設計では,ConvolutionレイヤとActivationレイヤを交互に複数回積み重ね後にPoolingレイヤを積み重ねた構成を基本ブロックと捉え,基本ブロックを複数回積み重ねた後にFFNNを積み重ねることが一般的である。
積み重ねるレイヤ・ブロックの総数や各Convolutionレイヤが抽出する特徴量の数は訓練データ次第であり,様々な条件で訓練して最適な条件を見極める必要がある。
5 訓練を促進するモデルの設計
Deep Learningモデルはレイヤを積み重ねるほど複雑な特徴量を抽出できるようになり,原理的にはモデル出力≒目標を達成しやすくなるはずである。しかし,パラメータ自動調整法には「レイヤを積み重ねるほど自動調整中のパラメータが異常な値に陥りやすく,訓練不良に帰結しやすい」問題がある。Deep Learningモデルは出力≒目標を達成できる高いポテンシャルを有するが,出力≒目標に至るまでのパラメータ自動調整が不安定であると理解すればよい。
この訓練不良は,パラメータ自動調整法の改良25-30)だけでなく,モデル設計の工夫によっても低減することができる。本節では,訓練不良を低減する代表的なレイヤおよびブロックについて述べる。それらは前節までに述べたFFNN,RNN,CNNの何れにも使用可能である。
5.1 Dropoutレイヤ
1.3節で述べた通り,特徴抽出レイヤは目標に強く影響する有意な特徴量だけでなく,目標と偶然相関した誤特徴量も抽出(過学習)する。誤特徴量も抽出する異常な値に陥った特徴抽出レイヤのパラメータは自動調整中に復旧され難く,訓練不良に帰結しやすい。
Dropoutレイヤ31)の機能は,ランダムな特徴量数の削減により誤特徴量の抽出を抑制し,訓練不良を低減することである。有意な特徴量は一般的に誤特徴量より目標への影響が強いため,特徴量数を削減すると有意な特徴量が優先的に抽出される。Dropoutレイヤは,値0を乗算するマスキングにより疑似的に特徴量数を削減する(Fig. 8)。即ち,特徴抽出レイヤの後にDropoutレイヤを積み重ねると,特徴抽出レイヤが抽出した特徴量の幾つかをDropoutレイヤはランダムに選択し値0を乗算する。乗算されなかった特徴量には有意な特徴量が優先的に抽出され,誤特徴量の抽出が抑制される。このランダム選択を伴う有意な特徴量の抽出を繰り返すと,特徴抽出レイヤが抽出した全ての特徴量が有意な特徴量となる。ランダムに選択する割合は訓練データ次第であり,様々な条件で訓練して最適な条件を見極める必要がある。

5.2 Normalizationレイヤ
特徴抽出レイヤの内部演算で使用する加重平均では,重みパラメータの絶対値が大きくなると,演算結果の特徴量が±∞に接近しやすい。この異常に絶対値が増大した値が入力される後続レイヤでは,自動調整中のパラメータも異常な値に陥りやすく,訓練不良に帰結しやすい。
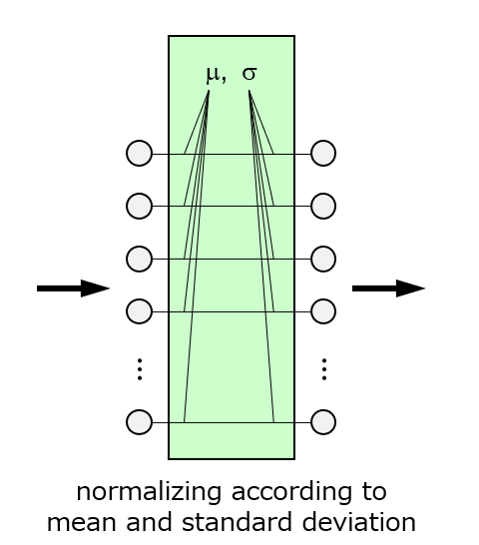
Normalizationレイヤの機能は,正規化演算により特徴量の絶対値増大を抑制し,訓練不良を低減することである(Fig. 9)。即ち,特徴抽出レイヤの後にNormalizationレイヤを積み重ねると,特徴抽出レイヤが抽出した特徴量から平均値を減じ標準偏差を除して正規化する(正確には正規化後に線形変換を伴う)。正規化された特徴量は平均値0,標準偏差1となるため,特徴抽出レイヤが抽出した全ての特徴量において絶対値増大が抑制される。Normalizationレイヤは正規化の範囲に種類があり,入力ごとに抽出した全特徴量を正規化するものをLayer Normalizationレイヤ32),特徴量ごとに複数の入力から抽出した特徴量を正規化するものをBatch Normalizationレイヤ33)と呼ぶ。
各節で述べてきたモデル設計の基本指針を集約すると,特徴抽出レイヤの後はActivationレイヤ,Dropoutレイヤ,Normalizationレイヤを単独または組合せて積み重ねることになる。組合せて積み重ねる場合はNormalizationレイヤ,Activationレイヤ,Dropoutレイヤの順番が一般的である。
5.3 Residual Block, Skip Connection
Deep Learningモデルは各レイヤを直列に積み重ねるだけでなく,1つのレイヤ出力を分岐して複数の後続レイヤを積み重ねる設計や,複数のレイヤ出力を統合して1つの後続レイヤを積み重ねる設計も可能である。分岐は1つのレイヤ出力を複数にコピーすることが一般的であり,統合は複数のレイヤ出力を加算,積算または結合することが一般的である。加算または積算による結合は,複数のレイヤ出力が同一サイズの場合のみ可能であることに注意されたい。
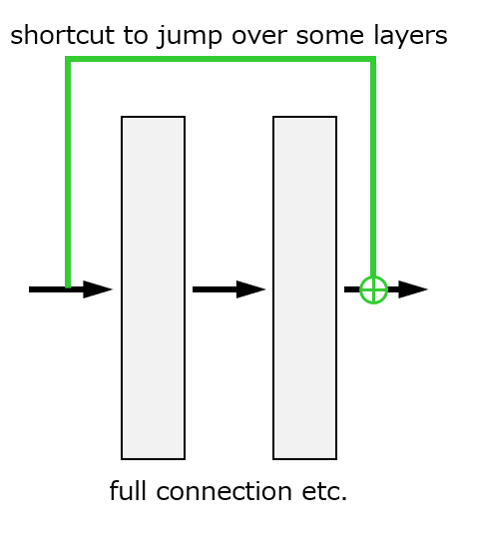
Residual Blockの機能は,分岐・統合を使用して迂回ルートを設けることにより,訓練不良を低減することである(Fig. 10)。即ち,Residual Blockは入力を2分岐し,一方は何もレイヤを積み重ねない迂回ルートとし,他方は特徴抽出レイヤを積み重ね,最後にそれらを加算する。パラメータ自動調整法の問題の原因(勾配消失)に関わるため詳細は割愛するが,迂回ルートを設けると原因が緩和され,訓練不良が低減する。Residual Block34)における迂回ルートのように,離れたレイヤ間を結ぶ接続をSkip Connectionと呼ぶ。
6 Deep Learningモデルの設計事例
本節では,これまで述べてきたDeep Learningモデルの設計指針に基づき予測モデルを構築・訓練した事例を紹介する。
6.1 液晶組成物の物性予測モデル
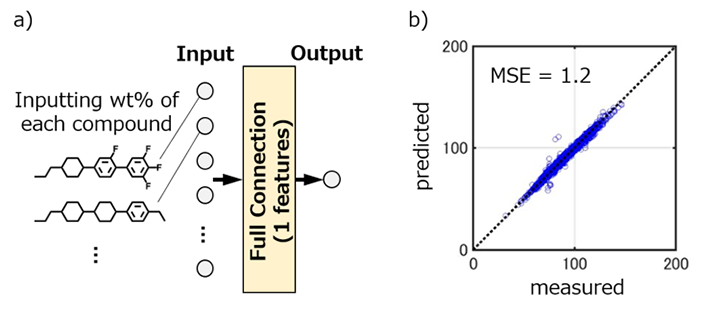
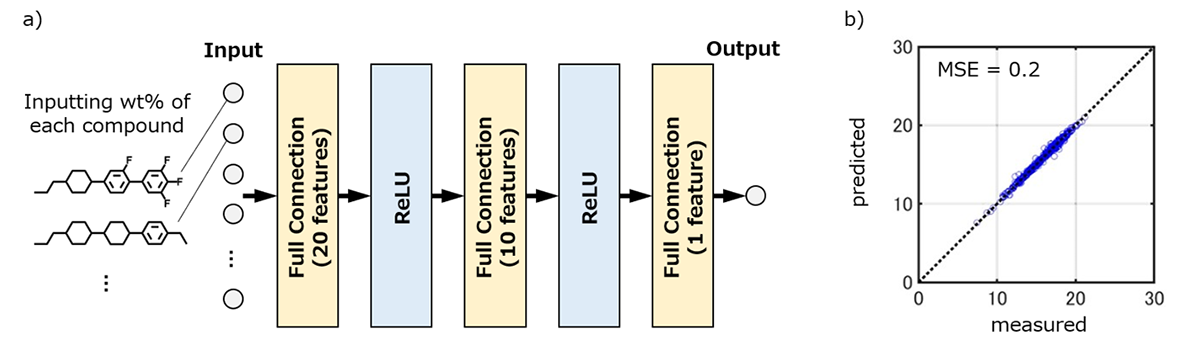
液晶原体の配合組成比と複数の要求物性を並べた数値テーブルを作成し,物性ごとにFFNNモデルを構築・訓練した。積み重ねるレイヤの総数などの最適条件を探索した結果,ネマチック相-等方相転移温度はFig. 11に示すFull Connectionレイヤ数が1層の予測モデルが最適であった。このモデルは一次関数を用いた重回帰と同義であり,配合組成比と相転移温度は線形関係にあることを意味する。一方,弾性定数はFig. 12に示すFull Connectionレイヤ数が3層の予測モデルが最適であった。レイヤ数が比較的多いことから,液晶組成物の巨視的な弾性変形の背景には液晶原体間の複雑な相互作用が存在すると解釈できる。
6.2 顔料の耐光性予測モデル
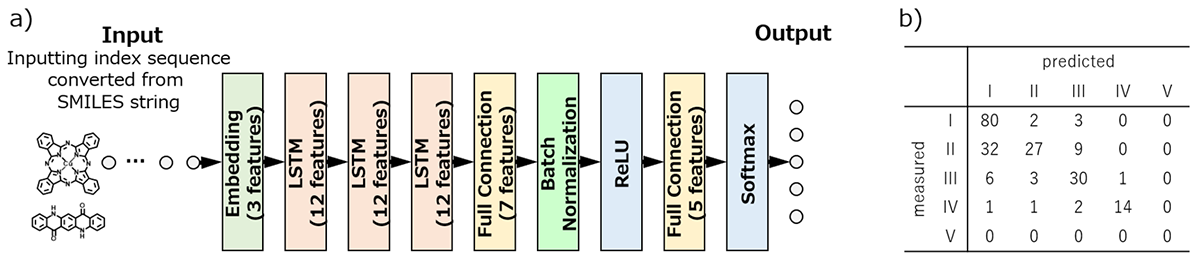
SMILES表記した顔料の化学構造と塗膜耐光性35,36) を並べた時系列データを作成し,RNNモデルを構築・訓練した。積み重ねるレイヤの総数などの最適条件を探索した結果,Fig. 13に示すLSTMレイヤ数が3層の予測モデルが最適であった。このモデルは正解率72%とそれほど高精度ではなかったが,顔料の粒子としての性状や塗膜中のビヒクルとの相互作用を考慮しない条件では十分な精度と考えられる。
7 結言
他の機械学習手法と比較したDeep Learningの最大のメリットは,訓練データから特徴量を自動抽出できることである。このメリットを享受するためには,訓練データに適したDeep Learningモデルの設計が重要であり,本稿では使用するレイヤの概略とモデル設計の基本指針について述べてきた。本稿を糸口に書籍やネット情報を読み解けば,自身の機械学習タスクに適したDeep Learningモデルを設計できるだろう。肝要なことは,最初から最適なDeep Learningモデルを設計しようとせず,様々な条件のDeep Learningモデルを構築・訓練し,設計の勘所を体得することである。奇妙あるいは残念に感じるかもしれないが,コンピュータを駆使したDeep Learningの世界でも,技術者の勘と経験が物を言うことを忘れてはならない。
最後に,本稿では割愛したDeep Learningの極めて魅力的な能力について言及する。それは,訓練データに類似した「新たなデータを生成」できる能力である。英文から日本語訳を生成するウェブ翻訳サービス37)や,高品質のフェイク人物画像を生成するウェブアプリ38)がデータ生成の代表例である。マテリアルズインフォマティクスの分野では,所望物性を発現する新規化学構造の生成や,所望物性を発現する複合材料モルフォロジー画像の生成などにデータ生成能力を活用できる。Deep Learningによるデータ生成を実践するためには,Variational Autoencoder39-41)やGenerative Adversarial Networks42,43)などの生成フレームワークを習得しなければならない。生成フレームワークは,複数のモデルを有機的に訓練させる難解な動作原理に基づくが,各モデルを構成するレイヤとモデル設計の基本指針は本稿記載と変わりはない。多くの読者がDeep Learning中級者となり, Deep Learningを活用したデータ生成にチャレンジすることを願う。
謝辞
Deep Learningモデルの設計事例で紹介した研究へのご尽力と,本稿の文章構成にご助言をいただいたDS1グループの中谷泰博氏,山﨑雄大氏に深く感謝いたします。
参照文献
- 斎藤康毅,“ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装”,オライリージャパン (2016)
- 斎藤康毅,“ゼロから作るDeep Learning ❷ ―自然言語処理編”,オライリージャパン (2018)
- 斎藤康毅,“ゼロから作るDeep Learning ❸ ―フレームワーク編”,オライリージャパン (2020)
- 斎藤康毅,“ゼロから作る Deep Learning ❹ ―強化学習編”,オライリージャパン (2022)
- "TensorFlow.", TensorFlow, https://www.tensorflow.org/
- "Keras: the Python deep learning API”, Keras, https://keras.io/
- "PyTorch.", PyTorch, https://pytorch.org/
- 竹内一郎, 烏山昌幸,“サポートベクトルマシン”,講談社 (2015)
- 坂本俊之,“作ってわかる! アンサンブル学習アルゴリズム入門”,シーアンドアール研究所 (2019)
- “DataRobot AI Cloud - The Next Generation of AI”, DataRobot, https://www.datarobot.com/
- 松尾豊,“人工知能は人間を超えるか ディープラーニングの先にあるもの”,P134,アグネ承風社 (2015)
- Frank Rosenblatt, “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain”, Psychological Review, 65(6), 386-408 (1958)
- Frank Rosenblatt, “Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms”, Washington DC: Spartan Books (1961)
- 福島邦彦, “位置ずれに影響されないパターン認識機構の神経回路のモデル―ネオコグニトロン―”, 電子情報通信学会論文誌 A, 10, 658-665 (1979)
- David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams, “Learning representations by back-propagating errors”, Nature, 323, 533–536 (1986)
- “ImageNet Large Scale Visual Recognition Challenge 201 2 (ILSVRC2012)”, ImageNet, https://image-net.org/challenges/LSVRC/2012/
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks”, NIPS, 1106-1114 (2012)
- Sepp Hochreiter, Jürgen Schmidhuber, “Long Short-Term Memory”,Neural Comput. 9, 1735-1780 (1997)
- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling, “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling”, https://arxiv.org/abs/1412.3555 (2014)
- David Weininger, “SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules”,J. Chem. Inf. Comput. Sci., 28, 1, 31–36 (1988)
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin, “Attention is All You Need”, NeurIPS, 5998-6008 (2017)
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, https://arxiv.org/abs/1810.04805 (2018)
- Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, “Improving Language Understanding by Generative Pre-Training”, https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (2018)
- Yann Le Cun, Léon Bottou, Yoshua Bengio, Patrick Haffner, “Gradient-Based Learning Applied to Document Recognition”, Proc. IEEE, 86, 11, 2278-2324 (1998)
- Ning Qian, “On the momentum term in gradient descent learning algorithms. Neural networks” Neural networks, 12(1), 145–151 (1999)
- Tijmen Tieleman, Geoffrey Hinton, “Lecture 6.5 - rmsprop, COURSERA: Neural Networks for Machine Learning”, https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (2012)
- John Duchi, Elad Hazan, Yoram Singer, “Gradient-Based Learning Applied to Document Recognition”, JMLR, 12, 2121-2159 (2011)
- Matthew D. Zeiler, “ADADELTA: An Adaptive Learning Rate Method”, https://arxiv.org/abs/1212.5701 (2012)
- Diederik P. Kingma, Jimmy Ba, “Adam: A Method for Stochastic Optimization”, ICLR, 1-15 (2015)
- Timothy Doza, “Incorporating Nesterov Momentum into Adam”, ICLR, 2013-2016 (2016)
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting”, JMLR, 15, 56, 1929−1958 (2014)
- Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E. Hinton, “Layer Normalization”, https://arxiv.org/abs/1607.06450 (2016)
- Sergey Ioffe, Christian Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, ICML, 448-456 (2015)
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Deep Residual Learning for Image Recognition”, CVPR, 770–778 (2016)
- “The Color of Art Pigment Database, an Artists Paint and Pigments Reference”, The Color of Art: Home - Pigments and Paints, http://www.artiscreation.com/Color_index_names.html
- ASTM D4303–10(2016), “Standard Test Methods for Lightfastness of Colorants Used in Artists' Materials”
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean, “Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, https://arxiv.org/abs/1609.08144 (2016)
- Ivan Perov, Daiheng Gao, Nikolay Chervoniy, Kunlin Liu, Sugasa Marangonda, Chris Umé, Mr. Dpfks, Carl Shift Facenheim, Luis RP, Jian Jiang, Sheng Zhang, Pingyu Wu, Bo Zhou, Weiming Zhang, “DeepFaceLab: Integrated, flexible and extensible face-swapping framework”, https://arxiv.org/abs/2005.05535 (2020)
- Diederik P Kingma, Max Welling, “Auto-Encoding Variational Bayes”, ICLR (2014)
- Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra, “Stochastic Backpropagation and Approximate Inference in Deep Generative Models”, NIPS (2014)
- Diederik P. Kingma, Danilo J. Rezende, Shakir Mohamed, Max Welling, “Semi-Supervised Learning with Deep Generative Models”, NIPS, 3581-3589 (2014)
- Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, “Generative Adversarial Nets”, NIPS, 2672–2680 (2014)
- Mehdi Mirza, Simon Osindero, “Conditional Generative Adversarial Nets”, https://arxiv.org/abs/1411.1784 (2014)
著者紹介(執筆時)
石井融
DIC株式会社
技術統括本部
データサイエンスセンター
DS1グループ
サイエンティスト
